![[Translate to English:] Illustration](/fileadmin/HIPS/__processed__/b/6/csm_WebNews_DataLeakage_0f01015fba.png)
Saarbrücken, 24. Oktober 2024 – Die Kombination von computerbasierter und experimenteller Forschung hat in den letzten Jahrzehnten beachtliche Erfolge hervorgebracht, von der Entschlüsselung genetischer Codes bis hin zur Vorhersage komplexer Proteinstrukturen. In diesem Jahr wurden Grundlagen dieser Forschung nun auch mit den Nobelpreisen für Physik und Chemie gewürdigt. Die zunehmende Verfügbarkeit von Methoden der künstlichen Intelligenz (KI) hat in der jüngeren Vergangenheit zahlreiche neue Anwendungsfelder der Bioinformatik eröffnet. Doch mit den neuen Möglichkeiten kommen auch Herausforderungen, die zunächst oft im Verborgenen bleiben. Eine der größten Herausforderungen bei der Entwicklung KI-basierter Anwendungen in der Bioinformatik, sind sogenannte Datenlecks.
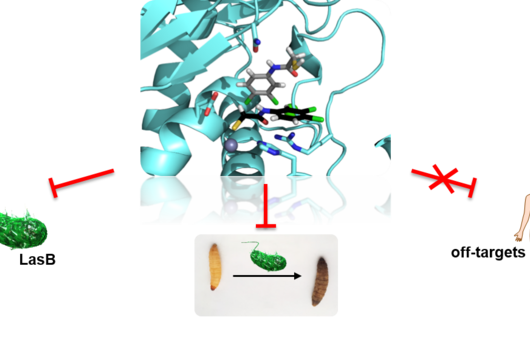
Forschende am Helmholtz-Institut für Pharmazeutische Forschung Saarland (HIPS) konzentrieren sich in erster Linie darauf, neue Wirkstoffkandidaten zu finden und für die Anwendung am Menschen zu optimieren. Die Forschungsgruppe Wirkstoffbioinformatik von Prof. Olga Kalinina nutzt modernste bioinformatische Techniken, um bisher unbekannte Resistenzmechanismen oder die Wirkungsweise neuer Wirkstoffe vorherzusagen. Dabei kommen zunehmend KI-Modelle zum Einsatz, die auf Basis großer Datenmengen trainiert werden, um aus Beispielen Muster zu erkennen und so verlässliche Vorhersagen zu treffen. Im Anschluss wendet das Modell seine gelernten Muster an, um auch neue, ihm bislang unbekannte Testdaten, zu analysieren. Dies stellt sicher, dass die KI nicht einfach auswendig gelernte Muster reproduziert, sondern wirklich generalisierbare Erkenntnisse gewinnt. Finden sich Teile der Trainingsdaten auch in den Testdaten, spricht man von sogenannten Datenlecks.
In einem gemeinsamen Übersichtsartikel in der Fachzeitschrift Nature Methods hat ein internationales Team von Data Scientists unter Mitwirkung von Kalinina umfassend aufgezeigt, wie problematische Datenlecks in der biologischen Forschung entstehen und wie man diese beheben oder ihnen sogar vorbeugen kann. Treten Datenlecks auf, kann das Modell auf Informationen zugreifen, die in der Realität nicht verfügbar sind, und so Vorhersagen treffen, die optimistisch, aber letztlich nicht tragfähig sind. Dies ist besonders in der pharmazeutischen Forschung relevant, wo fehlerhafte Vorhersagen die Grundlage für teure Experimente oder Versuche an lebenden Organismen sein können.
„Der Einfluss von KI auf die pharmazeutische Forschung und die Medikamentenentwicklung wächst zusehends. Vorhersagen von KI können erhebliche Auswirkungen haben, nicht nur auf den Erfolg oder Misserfolg von Forschungsprojekten, sondern auch auf das Leben von Menschen“, betont Roman Joeres, Co-Autor der Studie und Doktorand in Kalininas Forschungsgruppe. Ein KI-Modell, das auf falschen Daten trainiert wurde, kann falsche Ergebnisse liefern – ein Risiko, das schwerwiegende Folgen haben kann, besonders wenn am Ende der Entwicklung beispielsweise eine Krankheitsdiagnose oder die Entwicklung lebensrettender Wirkstoffe steht.
Ein bezeichnendes Beispiel zeigt, wie dramatisch sich Datenlecks auf die Performance einer KI auswirken können: Eine KI sollte Tumore auf CT-Scans erkennen und erzielte im Training beeindruckende Ergebnisse. Doch in der Praxis versagte sie. Der Grund: In den Trainingsdaten waren auf Tumorbildern Lineale abgebildet, da Ärzt:innen die Tumore vermessen hatten. Die KI „lernte“, Bilder mit Lineal als Tumor-Bilder zu klassifizieren, konnte jedoch in der Praxis ohne diese Markierung keine Tumore erkennen. Dies verdeutlicht, wie problematisch es sein kann, wenn die KI auf Merkmale trainiert wird, die später in der Anwendung fehlen.
Die Lösung, die die Autor:innen vorschlagen, ist ebenso anspruchsvoll wie notwendig: Sie empfehlen klare Richtlinien, um Daten aufzuteilen und zu validieren. So soll sichergestellt werden, dass KI-Modelle wirklich das lernen, was sie sollen – und nicht nur, was in den Daten möglicherweise sonst noch versteckt ist. Diese Maßnahmen könnten dazu beitragen, die Zuverlässigkeit von KI-Modellen in der naturwissenschaftlichen Forschung zu erhöhen und somit langfristig zu gewährleisten, dass neue Entdeckungen nicht auf fehlerhaften Annahmen basieren.
Das mag im ersten Moment wie ein weit entferntes, technisches Problem erscheinen, aber die Auswirkungen sind weitreichend. Wenn ein Modell zur Vorhersage von Proteinstrukturen aufgrund eines Datenlecks ungenaue Ergebnisse liefert, könnte dies zu fehlerhaften Experimenten und letztlich zu kostspieligen Rückschlägen in der Forschung führen. In der medizinischen Praxis, etwa bei der Diagnose schwerer Erkrankungen, könnten solche Fehler sogar gefährliche Konsequenzen haben.
„Wir müssen uns der Struktur und den Ursprüngen unserer Daten sehr bewusst sein, um Datenlecks zu vermeiden. Unsere Publikation versucht den Fokus auf das schnell übersehene Problem der Datenlecks zu lenken und in der wissenschaftlichen Community ein Bewusstsein dafür schaffen, um zukünftig bessere KI zu entwickeln“, sagt Kalinina. Das Problem liegt nicht nur darin, dass biologische Daten oft komplex und unübersichtlich sind, sondern auch darin, dass sie in vielen Fällen miteinander verknüpft sind. Dieser Aspekt der Forschung ist nicht nur eine technische Notwendigkeit, sondern auch eine ethische Verpflichtung. Denn schließlich geht es auch darum, dass Wissenschaft zuverlässig, transparent und vertrauenswürdig bleibt – gerade, wenn sie durch KI unterstützt wird. Die Arbeit Kalininas und ihrer Kolleg:innen ist daher ein wichtiger Schritt auf dem Weg zu einer Zukunft, in der KI und experimentelle Forschung Hand in Hand arbeiten, um die großen Herausforderungen unserer Zeit zu lösen.
OriginalpubliKation:
Bernett, J., Blumenthal, D.B., Grimm, D.G. et al. Guiding questions to avoid data leakage in biological machine learning applications. Nat Methods 21, 1444–1453 (2024). DOI: 10.1038/s41592-024-02362-y
![[Translate to English:] Illustration](/fileadmin/HIPS/News/WebNews_DataLeakage.png)
















![[Translate to German:] Alexandra K. Kiemer, Simon Both, Martin Empting](/fileadmin/HIPS/__processed__/c/6/csm_Kiemer_Both_Empting_7700535100.jpg)



































![[Translate to German:]](/fileadmin/HIPS/__processed__/c/9/csm_HZI_wiss_hemmhof_mik_001_611abc3df4.jpg "[Translate to German:]")


![[Translate to German:]](/fileadmin/HIPS/__processed__/1/b/csm_Andreas_Keller_2023_org_029c5088c1.jpg "[Translate to German:]")

![[Translate to German:]](/fileadmin/HIPS/__processed__/b/3/csm_AufDiePlaetze_WID-8615_4ee837e55b.jpg "[Translate to German:]")

























![[Translate to Deutsch:]](/fileadmin/HIPS/__processed__/2/b/csm_HZI_wiss_pseudomonas_cpi_hzi_001_62730ae12d.jpg "[Translate to Deutsch:]")